2024년 3월 26일 MySQL-Grammar
지난 시간에 SQL에 대해서 설치해보고 간단하게 구문 몇 개 다뤄봤는데 오늘은 문법에 대해서 알아볼꺼야

어제 만들었던 kdt 데이터베이스를 사용하기 위해서 use를 이욯하고 실행을 시킬려면
드래그하고 Ctrl + Enter를 누르면 실행이 될꺼야 앞으로 모든 실행은 이렇게 하면되
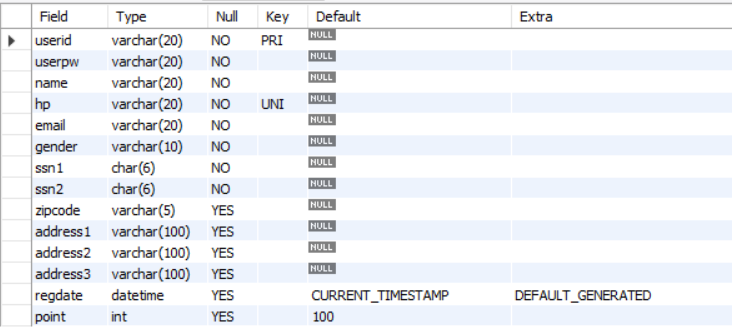
member테이블을 확인하면 어제 만들었던 필드나 타입들이 그대로 있지 오늘 이걸 활용해 볼꺼야

먼저 테이블 삭제하기는 실행시키면 해당 테이블이 삭제되는거고
alter를 사용해서 필드를 추가, 수정, 삭제를 할 수 있어 이것만 있다고 되는건 아니야
명령어를 사용해서 필드명과 타입을 적어서 해주는거지
add를 사용해서 추가시켜주고 modify column은 열을 수정하는거고 drop을 이용해서 삭제도 하지


mbti라는 필드를 생성해서 맨 맽에 문자형타입으로 생성이되었고 20자로 바꾸니까 바뀐게 보이지

CRUD(Create Read Update Delete) : 생성, 읽기, 수정, 삭제
생성은 당연히 테이블 생성할 때 사용하는 문법이고, 나머지는 필드나 값의 변화를 위해 사용되
insert는 테이블안에 값들을 삽입하고 싶을 때 사용하고 있지

C로 테이블 만들고 단어의 eng, 뜻의 kor 레벨의 lev를 집어넣고 단어는 중복이 없으니까
기본 키인 Priamary key로 지정해두는거야 뜻도 있어야되니까 not null, 레벨도 숫자형이라 int

insert를 이용해서 데이터 삽입을 해볼까 각 eng, kor, lev순으로 적으면 될꺼야
필드의 개수가 3개라서 값은 3개를 무조건 적어줘야해 null값을 줘도 상관은 없어
그리고 kor에 not null조건을 걸어둬서 뜻에 null값을 넣을 수는 없어
그리고 꼭 단어, 뜻, 레벨 순으로 안적어도 되고 첫 번째 단어필드가 왔으면 첫 번째에 단어값이 오기만하면되
그래서 보면 사과랑 바나나, 오렌지, 멜론, 아보카도가 추가되었지
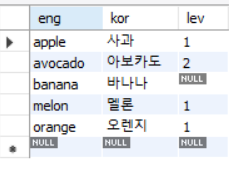
그럼 이렇게 추가가 된거지

아까 실행시켜줬던 member 테이블에 이 값들을 넣어줄꺼고 좀 있다가 활용할꺼야

이건 값들이 들어가 있고 약간 바뀌어 있는데 신경 안써도 되

update를 사용하여 데이터를 수정해보자 일단 먼저 safe모드를 해제줘서 수정할 수 있도록 세팅해놨어
레벨을 1로 만들어주는거고 포인트를 50씩 더해주고 다시 포인트에 넣어줘서 각각 유저들한테 줬어
그리고 where절을 이용해 아보카도만 레벨2로 올려주고 뜻 과 레벨을 바꿔줄 수도 있어

member테이블에 값들이 null으로 되어있었는데 해당 값들로 수정을 해줬어 위에 캡쳐본에서 처럼 된거지

삭제도 delete를 사용해서 원하는 값이나 한꺼번에 삭제할 수 있어


테이블에서 값들을 찾는거야 그래서 그 값들이 그대로 출력이 되는거지 아무것도 없으면 아무것도 안나오고
연산하면 연산한 값 *를 사용하면 모든 값들을 가져오는거 모든 필드를 적고 부르는거랑 똑같다고 보면 되지



3개의 문장을 활용해서 알아볼꺼야 where절 뒤에 오는 =기호는 같다는라는 의미로 비교연산자에 해당하니까 노헷갈~~
'apple'이라는 유저아이디일 때 유저아이디랑 이름을 알려달라는구문
남자일 때 유저아이디랑 이름을 알려달라는 구문
남자일 때 성별까지 알려달라는 구문
포인트가 150이상일 때 유저아이디랑 이름, 포인트를 알려달라는 구문 이야


is를 사용해서 양쪽이 같으면 null을 출력해주는 구문

문자열을 표현할 때는 '%'를 활용한다

order by절을 사용해서 정렬을 하는건데 where절은 굳이 안적어도 되고 뒤에 오름차순,내림차순도 생략이 가능해


체리 유저 추가해주고 오름차순으로 정렬


조건이 붙으면 where절을 사용하면 되고 오름차순도 생략이 가능해

limit를 사용해서 원하는 데이터를 출력 받는 거야
limit 3을 적으면 위에서부터 3개를 보여주고 있어 위에서부터 인덱스도 0번부터 시작이야
member 테이블안에 있는 모든 열을 가져오는 구문이랑 6개가 출력됨.

유저아이디의 갯수만큼 출력
zip코드는 null을 세지 않기 때문에 1개 아까 김사과 작성한 거 때문에
이름도 as '변경할 이름' 이렇게 하면 바꿀 수 있어


having절은 group by에 한해서 조건절이야

첫 번째 조건이 포인트가 100을 초과하는 이니까 where절에 넣어주고 그 다음 조건이 150이상인 포인트니까
having절에 넣어주는거고 포인트가 많은 성별을 우선으로 출력하라고 했으니까 내림차순으로 설정해줬어


정규화는 쉽게말해서 중복을 없애기 위해서 사용되는거라고 생각하면 될거 같아
데이터의 일관성과 무결성을 유지하면서 데이터베이스 구조를 최적화하는 데 중요한 도구야
비정규화는 정규화의 반대개념이라고 생각하면 될거같아

새로운 프로필 테이블을 만들었어
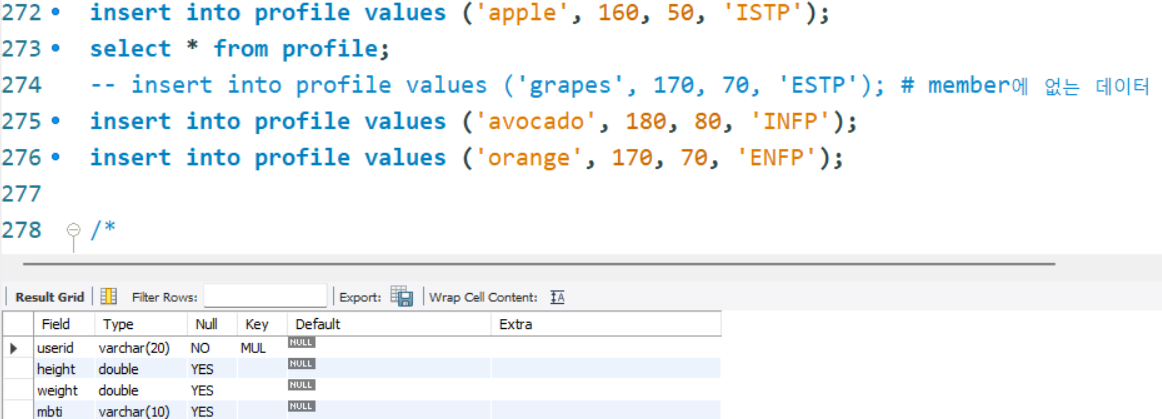
새로운 필드랑 값들도 추가시켜줬어 왜냐면 member테이블과 바로 다음에 배울 내용 때문이지

두 개의 테이블을 합치기 위해서 profile테이블을 만든거야

각 테이블을 적고 추가할 필드를 적는거지 유저아이디가 두 테이블에서 사용하고 있다는 조건이 일치하면서
member테이블의 name, gender가 profile에서는 mbti가 조인되어서 포함되는거지
그리고 왼쪽 오른쪽은 그냥 왼쪽기준으로 데이터를 출력하냐 오른쪽을 기준으로 출력하냐의 차이야 그냥
오늘은 배운 내용이 좀 많아서 힘드네 다음에 보자~~